|
|||||
STAViS Overview |
|||||
|
We introduce STAViS, a spatio-temporal audiovisual saliency network that combines spatio-temporal visual and auditory information in order to efficiently address the problem of saliency estimation in videos. Our approach employs a single network that combines visual saliency and auditory features and learns to appropriately localize sound sources and to fuse the two saliencies in order to obtain a final saliency map. The network has been designed, trained end-to-end, and evaluated on six different databases that contain audiovisual eye-tracking data of a large variety of videos. We compare our method against 8 different state-of-the-art visual saliency models. Evaluation results across databases indicate that our STAViS model outperforms our visual only variant as well as the other state-of-the-art models in the majority of cases. Also, the consistently good performance it achieves for all databases indicates that it is appropriate for estimating saliency "in-the-wild". The code is available at https://github.com/atsiami/STAViS. |
|||||
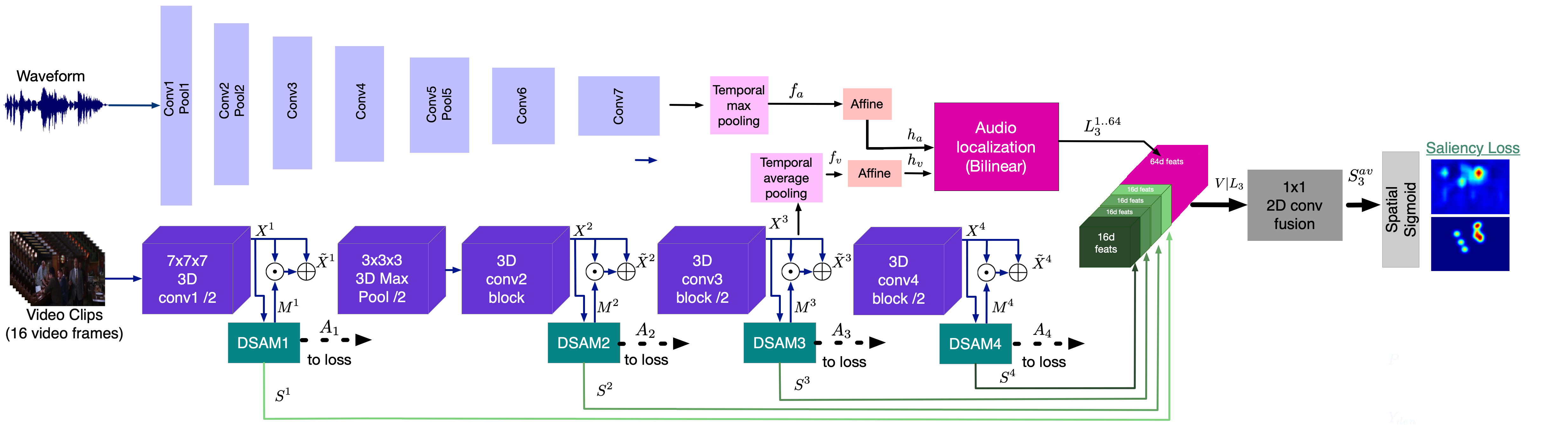
STAViS network architecture |
|||||
|
|||||
|
The proposed designed spatio-temporal audiovisual network for saliency estimation (Figure 2) consists of a spatio-temporal visual module that computes visual saliency, an audio representation module that computes auditory features, a sound source localization module that computes spatio-temporal auditory saliency, an audiovisual saliency estimation module that combines and fuses the visual and auditory saliencies, and finally, the appropriate losses. |
|||||
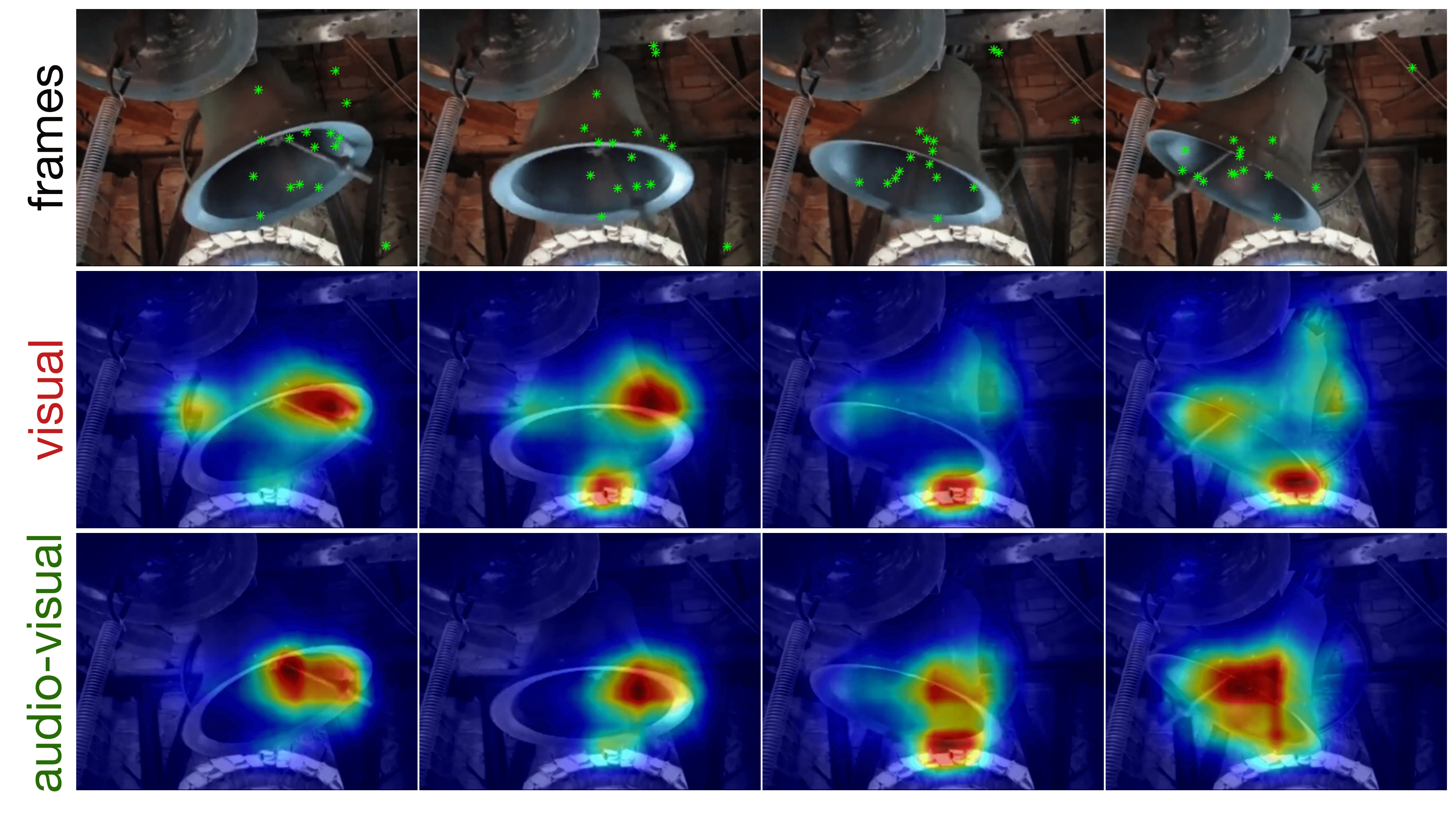
Sample results |
|||||
|
Evaluation on 6 different audiovisual eyetracking databases has been performed: AVAD, DIEM, Coutrot1, Coutrot2, SumMe and ETMD. Each database contains a variety of different types of stimuli. Also, we have compared our method to 8 state-of-the-art visual saliency methods. Some sample results can be found in the next videos. Details can be found on paper. |
|||||
|
|||||
|
|||||
|
|||||
Publications |
|||||
|
|||||
SoftwareThe code for end-to-end training of the STAViS network, as well as the code for testing and evaluation across the different datasets are available on GitHub. |
|||||
Data and modelsFor the easily reproduction of STAViS results, alongside with our pretrained models, we provide the extracted video frames and audio clips as well as the preprocessed ground truth saliency maps. You can download the pre-trained models as well as the data and the related files from here or use the script provided at code. |
|||||
